

This might be the unofficial seventh part of the “AI for DevEx” series. LLM tools are a great help during the entire software development process. But what if we are offline or if data privacy concerns disallow using ChatGPT and similar tools?
From the 16th to the 18th of December, we traveled from Europe to Southeast Asia to spend the next four months there. This inevitably implies a lot of time offline. But does that stop the coding fun? For sure, it will stop access to a LLM as a companion. Or?
Well, not necessarily. It turns out that local LLMs are pretty good, too.
The Backstory
Sunday, the 17th, 7:00 CET. I was sitting on flight TO2380 from Paris to Istanbul. I had planned to use the 3.5-hour flight productively by finishing up an architecture refactoring I was doing for a client.
The refactoring consisted of multiple steps and reduced the overall complexity and the amount of code engineers needed to change to add new functionality to the backend services. Up to this point, they had to touch at least two different services for every minor change. One of which was an artificial “gateway” service, unwrapping JSON requests, converting them to Protobuf, and sending them to another service via gRPC. Not only was this “gateway” a potential single point of failure, but it did not do anything meaningful but increase complexity. Therefore, we removed it and relied on a Kubernetes Ingress to dispatch requests based on the paths.
I had done most of the refactoring the weeks before, and everything was running in production; now, it was cleanup time. I quickly discovered that we had missed something in the attempt to remove the gateway that wasn’t used in production anymore. The local docker-compose setup still relied on this gateway service as the entry point. Therefore, I had to replace it with something resembling an Ingress.
I have used an nginx container in situations like this dozens of times. But gosh, what was the exact syntax for that default.conf file again?
Usually, I would quickly google it or ask ChatGPT. But this wasn’t possible here, 9000 meters up in the air. What else could I do?
Two things came to my mind:
- Searching my file storage for a project where I have already solved this. (Boooring, and maybe I wouldn’t find something on my disk)
- Haven’t I downloaded a LLM a few weeks ago for another project? (This sounds like fun. Let’s see where it gets me)
Quickly, I spun up my local LLM and asked it to generate some code to solve the task. It worked! But let’s step out of the story and look at the tools I have used for this.
Ollama – Local LLMs, offline
I tried downloading and running tools and LLMs locally, such as Llama.cpp, GPT4ALL , and Ollama. Ollama won for me in terms of ease of setup and usability.
Like other tools, Ollama allows to download and use various large language models. The llama2 family is the most popular one for general use. Still, there are others, such as codellama for generating and discussing code or wizard-math, a model for math and logic problems. You can find a full list of models here.
On a Mac, installation via Homebrew is straightforward:
brew install ollama
Once installed, we can start ollama via the command ollama serve. This starts a server that exposes a local REST API.
ollama serve.Ollama is also the client for this API, and we can now use the command ollama pull <model-name> to download a model. And ollama run <model> to run one. We can get help via ollama help.
ollama run llama2:13b I can send prompts to the model.Models such as llama2 come in different sizes. In this case, in 7b, 13b, and 70b (the number of parameters). On my trip, I had the 13b model with me, which is said to give better responses than the smaller 7b model but also requires at least 16 GB of RAM. The 13b version has a size of 7.3 GB on my drive. The 7b version only takes 3.8 GB of space.
Expectation Management
Do not expect these models to match GPT-3.5, let alone GPT-4. GPT-4 is said to have 1.7 trillion parameters. Compare this to the 13 billion of llama2:13b, and it should not be surprising that GPT-4 gives better results. Unfortunately, my M1 MBP with 64 GB RAM could not run a model of that size. 😅
I once tried llama2:70b, which needs at least 64 GB RAM according to the documentation, on this machine and it was really slow.
Case Study: Generating the Nginx Config with Ollama (llama2:13b)
While you have a lot of choices while connected to the internet, on the plane, I had exactly one. Fortunately, I still had a llama2:13b model on my computer. So, seeing how far I can get with this offline companion would be fun.

After a few seconds, the model returns a detailed (but not fully correct) response.
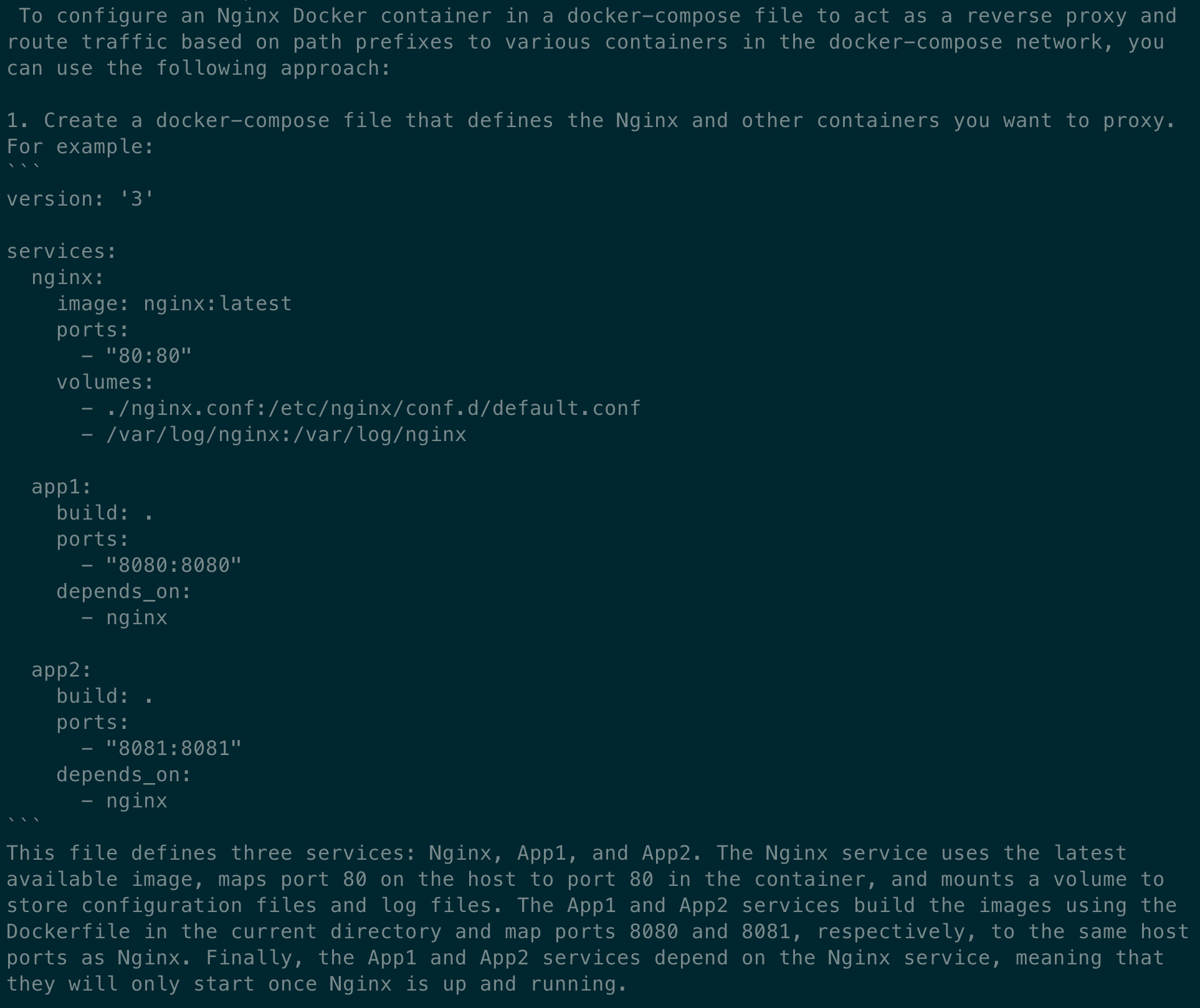
The first part contains Llamas suggestion for the docker-compose file. Overall, it looks pretty good. I would change a couple of things, such as the direction of the dependencies, but it is a good start.
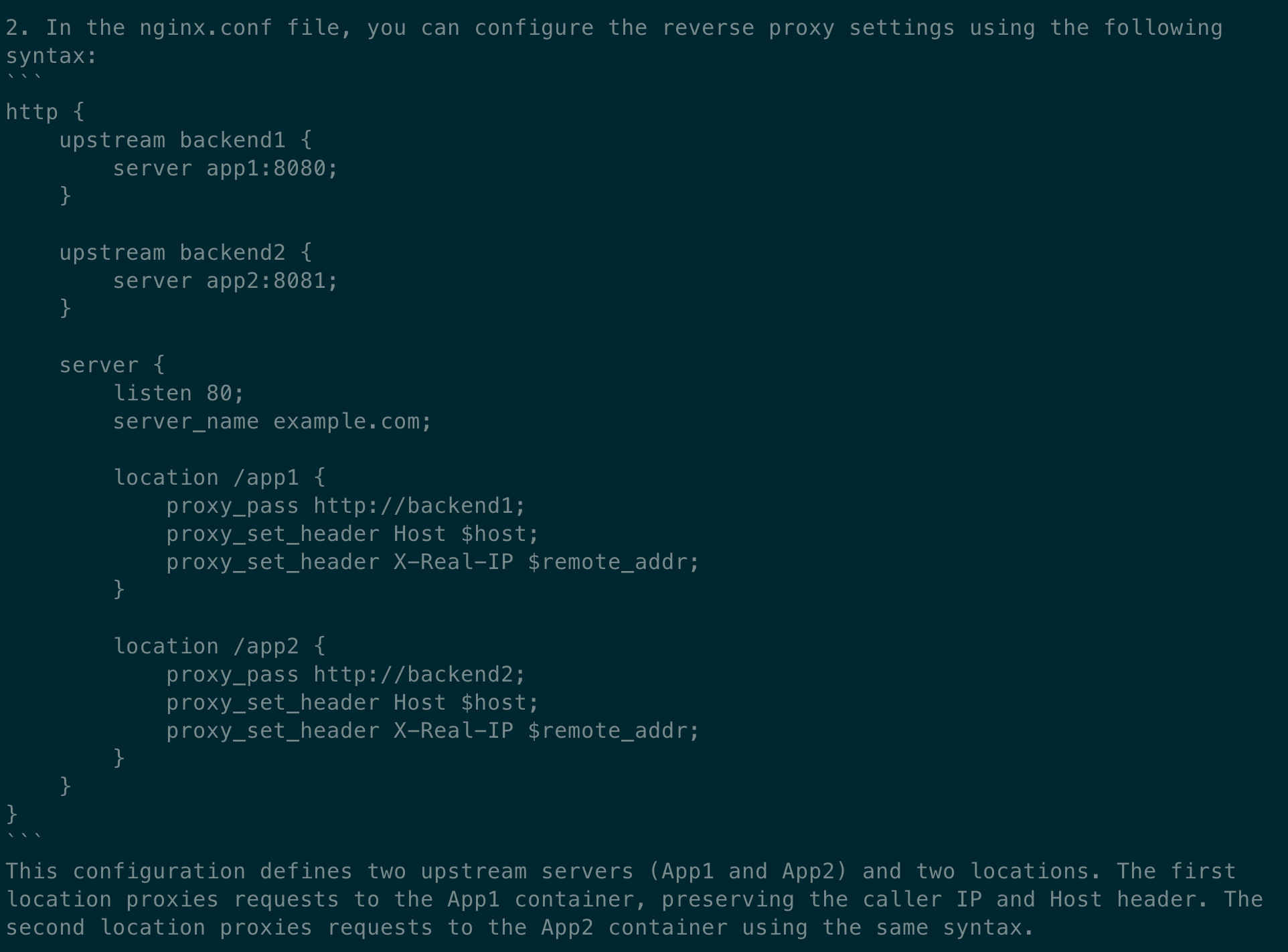
In the second part, the model explains what the nginx configuration should look like. I do not like the suggestion to define the upstreams separately, as we should be able to use the service names from the docker-compose file directly. When asked about it, the model confirmed that this should work, too.
Of course, I needed to do a couple of tweaks to the suggested configuration to suit my needs (after all, I did not provide a lot of context). But the llama2:13b model pointed me in the right direction. When starting the containers, I discovered a small mistake in the configuration: The nginx did directly expect the server part in the default.conf file, not wrapped in a http block. The fix was straightforward, and I had my local docker infrastructure ready.
It’s time to stow my laptop away and prepare for the landing. 😉
Conclusion
While local LLMs are not as powerful as GPT-4 and other models, they might be good enough to unblock us when SaaS tools are unavailable or not an option. Local LLMs can be a great alternative 9000 meters up in the air or when data privacy concerns make using OpenAI or other options impractical.
Because of the limitations of the models that we can run on laptops today, we need to be extra careful with the responses. Models like llama2 are even more prone to hallucinations and giving wrong responses than the much more powerful GPT-4 models we are used to.
Nonetheless, local LLMs are a thing, and it is still remarkable how well they perform in this example or conversations around well-known concepts, software design principles, and other topics. And all of that without the need for an internet connection.
Have you experimented with local LLMs? Which ones and what were your experiences?
